|

|
|
GOOGLE, TRACKING AND PRIVACY
Google talks of putting 1 in 20 Chrome download users in “FLoC” testing now underway; EFF researcher claims “breach of user trust”
Forging ahead on its “FLoC” initiative — pitched as privacy aware but seen as a power grab by competitors — Google is now testing — without explicit user consent — a new way of monitoring consumer web activity for advertisers. The testing may affect as many as 1 in 20 updating Chrome browsers downloaded in test nations, including the United States, but not the European Union.
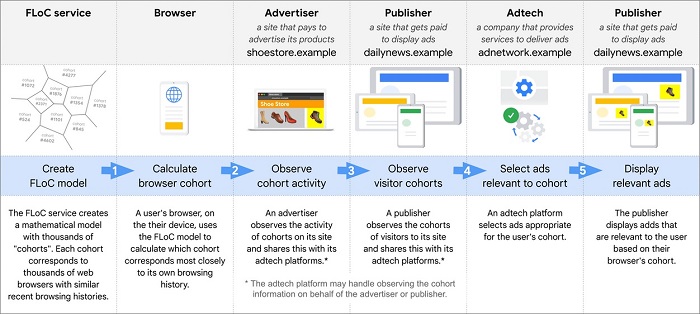
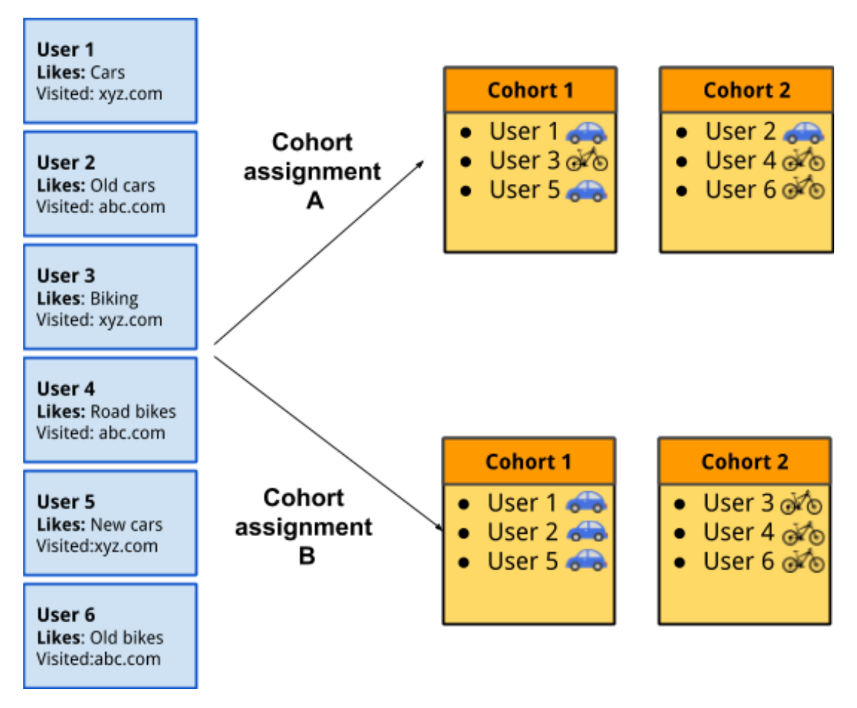
A story in Information Age, the web publication of the Australian Computer Society, included an diagram (above) of how FLoC cohorts might work. It was not clear who prepared the diagram, tagged just as “image supplied.” Meanwhile, a group of ad-tech companies announced an alternate plan called SWAN (See links below under, “Google Competitors React.”)
An Electronic Frontier Foundation researcher closely monitoring the so-called “origin test” of FLoC cohort matching system, called it a “breach of user trust.” The researcher, Bennett Cyphers, a 2017 MIT computer-science masters grad, continued in a post:
“Google’s launch of this trial—without notice to the individuals who will be part of the test, much less their consent—is a concrete breach of user trust in service of a technology that should not exist. Google has failed to address the harms of FLoC, or even to convince us that they can be addressed. Instead, it’s running a test that will share new data about millions of unsuspecting users. This is another step in the wrong direction . . . Google has failed to address the harms of FLoC, or even to convince us that they can be addressed. Instead, it’s running a test that will share new data about millions of unsuspecting users. This is another step in the wrong direction.”
For its part, Google announced the FLoC test in a developers’ blog post written by Marshall Vale, product manager of its “Privacy Sandbox” project. Vale calls the sandbox a “collaborative open-source effort . . . to develop a set of new privacy-preserving technologies that make third-party cookies obsolete and enable publishers to keep growing their businesses and keep the web sustainable, with universal access to content.”
For now, the only way for people to opt out of the tests is by disabling third-party cookies in the Chrome settings — though Google plans to offer an opt-out control in April, wrote TechCrunch reporter Frederic Lardinois in his account.
And a Google engineer, in a technical blog post, proposed the FLoC test be extended to 5% of all Chrome browser downloads in test regions from now until the testing ends July 13. “We’d like to request an increase from the standard “0.5% of page loads” origin trial usage target to 5%,” the engineer wrote, “because 0.5% of data would be too small for ad tech to train a sound ML model / to evaluate the effectiveness of the FLoC.”
Answering to points of criticism about FLoC, Vale wrote FLoC is designed to not share an individual’s browsing history outside of their Chrome browser. And he says the Chrome browser software — which will be busily matching a user to cohorts with like interests — won’t put a user in a so-called “sensitive” cohort that might raise issues of social, racial or medical justice or privacy. Google isn’t testing FLoC in the EU, without explanation.
There is no shortage of coverage of FLoC and concerns. A sampling is below.
- One thing Google has not emphasized is the apparent need for it to sample activity of millions of users to decide what “cohorts” to place the users in. Otherwise the browser cohorts would be unrelated and uncoordinated with each other. Who will audit that activity?
- Google has also not commented on criticisms that ad-tech companies which query the Chrome browser — and receive the numerical number of an interest cohort the user has been algorithmically placed in — could begin to match your interests to a off-line or ad-tech profile of an individual.
The Information Trust Exchange Governing Association, sponsor of this newsletter, proposed several years ago a cohort-based system — UDEX.ORG — to assemble targeting cohorts. It would run in the cloud, rather than on a proprietary browser, and be non-profit governed; data would be permissioned from the end user and the user’s ID encrypted.

GOOGLE’S FLOC TEST
GOOGLE COMPETITORS REACT
|
|
|
|
Does your organization need customized privacy compliance solutions? ITEGA can help.
|
|
|
|
We bring together support you need to approach compliance with CCPA, GDPR if needed, and future privacy legislation as it emerges.
|
|
|

|
PRIVACY AND ADVERTISING
Key IAB Tech Lab official departs as ad-tech industry struggles for full consensus on replacing “third-party” cookies with different privacy-oriented targeting plan
A key executive behind the IAB Tech Lab’s effort to create a more privacy-focused digital advertising ecosystem is leaving. Jordan Mitchell had the title SVP, Head of Consumer Privacy, Identity and Data at the tech lab, an industry standards and technology development nonprofit governed by advertising technology companies along with some advertisers and publishers. Mitchell has been in the digital ad business for 18 years, the last three at IAB Tech Lab.
“The enormous disruption to digital identifiers, data and consumer privacy is just beginning, and it’s a brilliant opportunity for the companies and people that embrace the disruption,” Jordan said in an April 2 note about his “extended break from work to spend time with my wife, play and relax.” He continued: “It’s a new world now. I’m incredibly bullish on digital media and ad-supported, personalized experiences, and the continued innovation driving both (responsibly).”
Mitchell has lead IAB TEch Lab’s “Project Rearc,” an effort to bring ad-tech companies together around a way to “re-architect” the way digital advertising works to target and deliver messages presumed to match the interest of users. The current technology is largely dependent on so-called “third-party cookies,” which browsers made by Apple, Mozilla, Microsoft and — next year — Google.
So far, there is no clear winning solution.
The closest thing to consensus is around Unified ID 2.0, proposed by leading ad-tech company The Trade Desk and set to be “operated” by PreBid.org, Inc. an industry consortium nonprofit. There is no clear understanding yet of what entity will govern operation of UID2.0.
AD TECHNOLOGY | Google RTB class action
ANTITRUST
WASHINGTON WATCH
TECH AND JOURNALISM
|
|
|

|
A Mozilla Foundation report seeks new governance forms to give more data control and benefit to individuals
The nonprofit entity which controls the Firefox browser released a second report this week in a series studying the challenge of how to govern and manage the privacy of digital data. The Mozilla Foundation report calls for rules around data experimentation that help with “rebalancing power towards individual agency, collective benefit and data rights.”
Mozilla set up a Data Futures Lab on Sept. 16 with the intention of fostering, and in some cases helping to fund, new approaches to governing the use of digital data.
The report, “What Helps? Understanding Needs and the Ecosystem for Support: An Ecosystem Study of Alternative Data Governance,” runs 48 pages and is based upon interviews with at least 114 global organizations engaged in supporting or building of data systems different from the current, centralized, platform-dependent world. The report says respondents said big tech corporations were dominant power players “who dominate teh market and continually fail to meet evolving standards of personal privacy and data rights.”
Principal author Katya Abazajian wrote March 31 that her team “identified seven approaches to governance that seek to challenge the way dominant platforms solely benefit from and maintain full control of data as a commodified, extractive resource.” It says alternate data governance should do at least one of these three things:
- Shift agency from data collectors to data subjects and beneficiaries in a meaningful way
- Share the benefits of data between various parties rather than concentrating most of all the value within a single organization
- Manage data in ways that represent multiple interest (the data collectors, data subjects or other beneficiaries of the initiatives.
A big challenge for such organizations is balancing social governance, tech implementation and business strategy, Abazajian writes. Promising user communities might include credit unions, trade unions or other collectives, she adds. One area tagged for further study — how to fund such building or support organizations.
PERSONAL PRIVACY
- Edelman’s new survey finds big declines in public trust of technology firms | Ina Fried & Mike Allen, Axios.com
- Blockchain Comes Under Data Privacy Scrutiny | Alfredo de la Cruz, Aren’t Fox law firm
- Tesla’s video footage of drivers raises safety and privacy concerns, EFF lawyer says | Joann Muller, Axios.com
- How to Stop Facebook From Spying on Your Internet Activity | Lance Whitney, PCMag.com
- If You Care About Privacy, It’s Time to Try a New Web Browser | Brian X. Chen, NYTimes.com | RELATED STORY
- How to see everything Google tracks about you and erase it | Kim Komando, USAToday.com
- Reporter tries to use ad-tech industry tool to manage privacy and finds it tough | Aaron Sankin, TheMarkup.com
- UC-Berkeley entrepreneur Dawn Song advises on how to regain personal privacy | S.C. Stuart, PCMag.com
- ESSAY: The Information Revolution Has Turned Us Into Digital Economic Objects | Peter S. Magnusson, DigitalPrivacy.News
- Contacts Access and Data Privacy Issues in Burgeoning Social Media Apps | Julie O’Neill, SociallyAwareBlog.com
BIOMETRICS AND PRIVACY
VACCINE ‘PASSPORTS’ AND PRIVACY
|
|
|
|
What is a hash, besides breakfast? Privacy lawyer explains part of the answer could be “reasonably”
For a non-technologist, some of the terms involved in considering the advance of privacy can be head scratching. One which comes up frequent is “hashing” — the application of a mathematics and programming to obscure a piece of data with the intention it being made more private — or difficult to hijack in transit from sender to authorized recipient and user.
Now David Z. Zetoony, a Colorado lawyer who has been among the most diligent explaining and following aspects of California’s new privacy laws, has provided a layman’s explanation in a March 31 blog post entitled, What is ‘hashing,’ and does it help avoid the obligations imposed by the new privacy regulations?
The key legal question is whether data which has been “hashed” is still considered “personal information” under either California or European Union regulations. That’s important, because if it isn’t, it could be subject to less stringent privacy and consent rules. Being a good lawyer, Zetoony doesn’t really answer that question, leaving it to cite regulatory language for readers to decide. Zetoony, with the Florida-based law firm of GreenbergTraurig LLP, says it may hinge in part on the meaning courts give to the word “reasonably” in California law.
CALIFORNIA PRIVACY | DARK PATTERNS
STATEHOUSE WATCH | Colorado bill
- Colorado Joins the Consumer Data Privacy Fray | Alissa Gardenswartz et al.,
- Brownstein Hyatt Farber Schreck law firm
- Colorado Introduces a Comprehensive Consumer Privacy Bill | Maya Atrakchi &Joseph J. Lazzarotti, Jackson Lewis law firm | RELATED STORY
- Privacy Bill Essentials: Colorado Privacy Act | William Ballentine et al., Hinshaw law firm
- ROUNDUP: Status Of Proposed CCPA-Like State Privacy Legislation As of March 29 | David Stauss, Husch Blackwell LLP
- Oklahoma Senate appears read to let tough, House-passed privacy bill die | Ben Felder, ReadFrontierorg
- Two similar Florida privacy bills making way toward Gov. DeSantis, who supports | Erin Jane Illman & Junaid Odubeko, Bradley Arant Boult Cummings LLC
- West Virginia Republicans Introduce California-Style Data Privacy Legislation | Maurice Wutscher, Consumer Financial Services Blog | RELATED STORY
- Private Right of Action May Again Poison Washington state’s Privacy Act | Andreas Kaltsounis, Baker & Hostetler law firmPrivacy Bill Essentials: Washington state proposal | Shalini Bhasker et al., Hinshaw Privacy & Cyber Bytes (law firm)
WORLD PRIVACY
UPCOMING EVENTS
|
|
|
QUOTE OF THE WEEK
Opening language from class-action lawsuit aimed at Google’s Real-Time-Bidding (RTB) services
“Through its various consumer-facing products and services – and its business advertising and surveillance tools – Google amasses data about billions of people for the purpose of creating detailed dossiers about them in furtherance of targeted advertising. Recognizing that American consumers have significant privacy concerns, however, Google makes two “unequivocal” promises to users who sign up for Google’s services: (1) “Google will never sell any personal information to third parties;” and (2) “you get to decide how your information is used.”Google also promises that it will not use certain sensitive information for advertising purposes. Google breaks these promises billions of times every day.
” . . . This Complaint identifies how Google actively sells and shares consumers’ personal information with thousands of entities, ranging from advertisers to publishers to hedge funds to political campaigns and even to the government, through its Google Real-Time Bidding system. The personal information that Google sells, shares and uses includes the very sensitive information Google promised it would not use for advertising purposes. These practices are not disclosed to consumers . . . Google account holders whose personal information is sold and disseminated by Google to thousands of companies through Google’s proprietary advertising auction process effectuated through real-time bidding (“RTB”) auctions . . . .
” . . . Few Americans realize that companies are siphoning off and storing that “bidstream” data to compile exhaustive dossiers about them. These dossiers include their web browsing, location, and other data, which are then sold by data brokers to hedge funds, political campaigns, and even to the government without court orders . . . the Google RTB process takes place in fewer than 100 milliseconds, faster than the blink of an eye. Google’s ability to provide a rich and highly personalized set of Bidstream Data for each Target is unprecedented and is the primary source of Google’s massive revenues. Google is a consumer data powerhouse unmatched in human history.
” . . . Through these services, Google surreptitiously observes, collects, and analyzes real-time information about everyone engaging on those platforms. This includes collecting and selling information about activity users could not expect to be sold. Google’s purpose is to build massive repositories of the most current information available about the people using its services to sell it to Google’s partners. But because transparency about those practices would lead to less user engagement on those platforms, which in turn would impede its ability to maximize targeted ad revenues, Google fails to make accurate, transparent disclosures about those practices to its account holders. Instead, Google promises its account holders privacy and control . . . The Bidstream Data that Google sells and discloses to thousands of Google RTB participants identifies individual account holders, their devices, and their locations; the specific content of their Internet communications; and even highly personal information about their race, religion, sexual orientation, and health.”
|
|
|
|
ABOUT PRIVACY BEAT
Privacy Beat is a weekly email update from the Information Trust Exchange Governing Association in service to its mission. Links and brief reports are compiled, summarized or analyzed by Bill Densmore and Eva Tucker. Submit links and ideas for coverage to newsletter@itega.org.
|
|
|
|
|
|


{kind=link}
{kind=link}